


Beth Mawhinney will receive her MLIS from the University of Denver in June. She is currently working as a Digital Assets curator at the University of Denver, and recently completed a "Wikimedian in Residence" internship in the Digital Collections Department with Special Collections and Archives.
When setting off on this Wikidata Sprint I had no idea how far down the Wikidata rabbit hole it would take me. I am an MLIS candidate with the University of Denver. A few quarters back I briefly played around creating linked data in Wikidata, while taking a Metadata Architectures course taught by UNLV’s Head of Digital Collections, Cory Lampert. The intrigue of linked data stuck with me, and I continued to connect with Cory about my journey as an MLIS student and where I might land after graduation. Like so many in this field, I am a second career person, having previously worked in social services. It's important to me not to start over, but connect these two parts of my life. I have seen first hand the positive and negative effects the creation, accessibility, and usability of records has on disparate community groups. Listening to where I came from and where I hope to go, Cory connected me with Darnelle Melvin, UNLV’s Special Collections and Archives Metadata Librarian and linked data expert.
How it Began
Once I connected with Darnelle, he explained that UNLV is currently conducting a Dean’s Leadership Circle funded Wikidata pilot, striving to make underrepresented materials from the UNLV Special Collections and Archives more discoverable through structured linked data in Wikidata. The pilot is being conducted in sprints, identifying themes or a focus of related archival materials and agents to describe in Wikidata simultaneously to easily represent the relationships between them in Wikidata. As Darnelle put it, “More bang for your buck!” I could not have been more eager. Conducting a Wikidata sprint was an actionable way I could help bring more visibility to underrepresented archival materials, and contribute to linked open data.
Wikidata Sprint Focus: UNLV’s Voices Exhibit
The Wikidata sprint I worked on focused on exposing the contents of the UNLV Special Collections and Archives Voices exhibit which aims to tell the stories of influential African Americans in the Las Vegas community by highlighting UNLV archival collections and oral histories. Using the Voices exhibit as a jumping off point, 31 agents including people or corporate bodies and 64 collections or oral histories were identified to be described in Wikidata. The Voices exhibit acted as a common thread tethering agents, collections, and oral histories together. Having a common theme and choosing related materials allowed for relationships between agents, events and archival materials to be represented in Wikidata linked data, expanding the rich descriptive context of these items. Describing related agents and materials also alleviated time and resources I would have spent on research. At the beginning of the sprint, I had been warned that it would be all too easy to fall down the Wikidata rabbit hole, get a little lost on the knowledge graph I was stitching together, and in all honesty at times I did. I would find and describe context that did not always directly relate to the goal of the sprint, making difficult decisions about what was important to represent. But having the Voices exhibit as a strong central guide also made it easier to get back on track.

Sprint Phases
The sprint took place in three phases:
- Creating an item record for the Voices exhibit and linking featured agents with the Wikidata property main subject (P921).
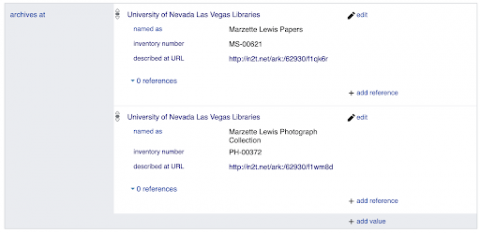
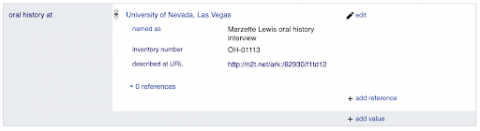
- Creating item records for each featured agent and linking to corresponding archival collections or oral histories with the Wikidata properties archives at (P485) or oral history at (P9600).
- Creating item records for archival collections and oral histories related to featured agents and linking to the corresponding ARK.
Layering the creation of these items in these phases layered relationships between the Voices exhibit, featured agents, and related archival collections and oral histories in the structured linked data of Wikidata statements. All featured agents were identified as the main subject (P921) of the Voices exhibit. As I created Wikidata items for featured agents, relationships quickly emerged identifying commonalities between agents such as employers, events, positions held, member affiliations, and more. Linking agents to corresponding archival collections or oral histories with the Wikidata properties archives at (P485) or oral history at (P9600) not only linked collections or oral histories back to the Voices exhibit but also to each other and UNLV libraries.
Layering of these relationships and descriptions created a rich knowledge graph in Wikidata which can be queried using the power of SPARQL. SPARQL is a semantic query language for databases, that provides users ways to experience the multi-layered relationships of data to answer their research questions. For example, the results of this SPARQL query: https://w.wiki/4t8f, provides a list of of every agent indicated as a value of the property main subject of the Voices Exhibit Wikidata item, which also contains statement on focus list of Wikimedia project (P5008) of WikiProject PCC Wikidata Pilot/University of Nevada, Las Vegas. This query illustrates the relationship between the Voices exhibit, the featured agents, and ultimately the UNLV Special Collections and Archives described in Wikidata during this sprint.
Sprint Tools and Properties
UNLV’s’ WikiProject page was central to me completing this Wikidata sprint. The page provides an extensive set of best practices and guidelines for describing agents and archival materials in Wikidata, which I referenced constantly throughout the sprint. The Voices exhibit was the first exhibit that would be described for this pilot, so prior to starting the sprint, Darnelle and myself developed a data model and matching Cradle form, tools to be used for creating a new archival entity: exhibit. A Cradle is a tool that supports uniform creation of new Wikidata items through a form with suggested properties. A data model is a list of properties used when a new exhibit item is created in Wikidata, accompanying use descriptions for each property, and provides example items for reference. These tools were added to UNLV’s WikiProject page to support myself during this sprint, as well as to support future sprints.
There a three Wikidata properties essential to this sprint which supported me to build the relationships between the items I described:
- main subject (P921) necessary to link agent items to the Voices exhibit
- archives at (P485) necessary to link archival collections items to agents and the UNLV libraries
- oral history at (P9600) necessary to link oral history items to agents and UNLV libraries
In Wikidata references are required to validate claims. To assign references to statements I mostly used the property reference URL (P854), linking statements to UNLV finding aids and the UNLV special collections portal. Using these tools and focusing on making claims using these properties helped shape this Wikidata sprint and supported me to efficiently and consistently describe the work of any targeted UNLV archival materials.
Why Wikidata?
Falling down the Wikidata rabbit hole was overwhelming at times to say the least, but going too deep and finding my way out ultimately helped me answer the question “Why Use Wikidata?” for myself. Sure, everything Darnelle explained to me about the Wikidata pilot before I started sounded great, but I still found myself wondering from time to time, “Why Use Wikidata?”. Working so extensively in Wikidata, I was able to see the impacts of my work unfold in real time, and what Wikidata really can be used for:
- Increasing visibility of underrepresented archival materials.
- Representing relationships between archival materials and agents.
- Creating persistent identifiers for local agent records.
- Leveraging Wikidata references to increase exposure to finding aids, institution websites, and collection portals.
- Easily contributing linked data to the semantic web.
For example, throughout this Wikidata sprint I created or enhanced over 100 Wikidata items representing or related to UNLV archival materials. I directly contributed to UNLV’s efforts to make underrepresented materials from the UNLV Special Collections and Archives more discoverable through Wikidata. Of these items, 21 represent agents who are not included in any national name authority file (i.e. LCNAF, SNAC, ULAN, FAST, VIAF). This in turn means I created persistent identifiers, Wikidata Q numbers, for these 21 agents, creating valuable resources for galleries, libraries, archives, and museums (GLAM) to use for future description work.
I also assigned over 900 references to statements during this sprint, the majority of which are direct links to UNLV finding aids, oral history transcripts on the UNLV Special Collections and Archives portal, or the Voices exhibit website further driving traffic toward UNLV archival materials. Working on this Wikidata sprint not only afforded me the opportunity to contribute to UNLV’s efforts to expose underrepresented archival materials, but now I have an actionable tool I will be able to employ in a purposeful way as I go into new spaces throughout my career, and surely encounter descriptive inequities and information gaps.
--by Beth Mawhinney
